The Tiobe index is really missing one piece of information about .Net for its users. Java is #1. So users should use Java, right? Well, maybe not. Let’s talk about the problems with it before we move on.
I am going to make an argument that:
- Java is actually a more clear #1 than suggested.
- .Net is #2 behind Java, but not as far behind as the Tiobe index makes it appear.
Problem 1 – DotNet Framework is not listed as one a language
.Net has more languages writing against it than just one. That makes it appear less popular because the language is more fragmented. In fact, two of them are in the top 5 or 6. However, the fact that a dll compiled in either language can be consumed by either language is really not described here. I am not saying this should be on the same list of programming languages, but Tiobe should make it clear that the combined .Net languages show .Net as being used more heavily. Similary for Java, there are other languages that compile to the JVM. Perhaps there should be a page on compile target: What percent of languages compile to .Net’s Common Intermediary Language or compile to the Java Virtual Machine or to machine code or don’t compile at all?
As for intermediary languages, there are only two that stand out: Java and .Net. And Java is #1 but it only has 1 in the top 10. .Net has two in the top 10 and the combined languages are easily a rival to the combined JVM languages.
Look at the Tiobe index and add up the .Net Framework languages:
.Net Framework Languages
| Language |
2019 Tiobe Rating |
| Visual Basic .Net |
5.795% |
| C# |
3.515% |
| F# |
0.206% |
| Total |
9.516% |
Notice that combined, the number of the three main .Net languages is %9.516. That puts .Net in the #3 position behind Java, C, and C++.
Problem 2 – Some .Net languages are missing and may be lumped in other languages
What about Visual C++? Yes, you can write .Net code in C++. However, that language is completely missing from Tiobe. Or is it? Is all Visual C++ searches lumped in with C++? If so, shouldn’t Visual C++ be separate out from C++. What is the Tiobe raiting Visual C++ would get? That would be hard to guess. But it is a language has been around for almost two decades. Let’s assume that a certain percentage of C++ developers are actually doing Visual C++. Let’s say it is more than F# but quite a lot less than C#. Let’s just guess because unlike Tiobe, I don’t have have this data. Let’ say it was .750. Again, this is a wild guess. Perhaps Tiobe could comment on this, perhaps they couldn’t find data on it themselves.
.Net Framework Languages
| Language |
2019 Tiobe Rating |
| Visual Basic .Net |
5.795% |
| C# |
3.515% |
| F# |
0.206% |
| F# |
0.206% |
| Total |
10.266% |
As you see, .Net combined is clearly #3 just by combining the .Net languages. Well past Python, which in fact can be used to both code for .Net (IronPython) and for the Java JVM (Jython). What percent of python is used for that?
Here is a wikipedia list of .Net-based languages: https://en.wikipedia.org/wiki/List_of_CLI_languages.
Similarly, for Java, languages like Groovy up it’s score. Here is a wikipedia list of Jvm-based languages: https://en.wikipedia.org/wiki/List_of_JVM_languages.
Problem 3 – Visual Studio is Awesome
For all the problems and complaints of bloat, Visual Studio is the move feature rich IDE by such a long ways that I doubt any other IDE will ever catch up to it, except may Visual Studio Code, which, however, is just as much part of the Tiobe index problem as Visual Studio is.
The better the tool, the less web searching is needed. The breadth of the features in Visual Studio is staggering. The snippets, the Intellisense, the ability to browse and view and even decompile existing code means that .Net developers are not browsing the web as often as other languages. My first search always happens in Intellisense in Visual Studio, not on Google. The same features and tooling in other IDEs for other languages just isn’t there. Maybe Exclipse, but only with hundreds for plugins that most developers don’t know about.
After Visual Studio 2012 released, the need to search the web has decreased with every single release of Visual Studio. I am claiming that C#, which is the primary .Net Framework language microsoft code for in Visual Studio, is used far more than Visual Basic .Net. Tiobe has Visual Basic .Net at 5.795% and C# at 3.515%, but reality doesn’t match Tiobe’s statististics. C# is used far more than Visual Basic .Net.
I am making the hypothesis that as the primarily coded language in Visual Studio, C# would appear to go down in the Tiobe index since the release of Visual Studio 2012. Let’s test my hypothesis by looking at the Tiobe year-by-year chart for C#. Do we see the Tiobe index going down starting with the release of VS 2012?
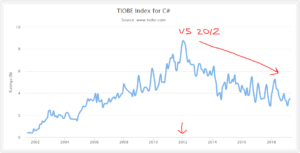
After looking at the Tiobe index, I am upgrading my claim from a hypothesis to a theory.
Other .Net languages may not experience the same as C# as the tooling in .Net is primarily focussed around C#.
So the reality is that the Tiobe index is showing the data it can find from search engines, but the data for C# is just not there because a lot of the number of ways C# deflects the need to search.
I hypothesise that C# reached a peak Tiobe index of 8.763% and it’s usage has not actually gone down. Instead, it has gone up. However, the data doesn’t exist to prove it. Assuming the hypothesis is correct, and C# usage has gone up, then the rate it should be is closer to 9 or 10. That means the C# is probably #3 on it’s own.
If we adjust to take this problem into account, simply by using the 2012 index and not assuming the the usage rate has gone up, we see the following:
.Net Framework Languages
| Language |
2019 Tiobe Rating |
| Visual Basic .Net |
5.795% |
| C# |
8.7% |
| F# |
0.206% |
| F# |
0.206% |
| Total |
17.606% |
Now, I am not saying .Net is above Java with my hypothesized 17.505% adjusted rating. Java has other languages as well that compile to the JVM that would similarly raise it and it is still #1.
Problem 4 – Direct linking to or searching on Microsoft.com
Microsoft has done a great job with a lot of their documentation. Some of this could be attributed to Visual Studio as well. After clicking a link in Visual Studio, we are taking directly to a site like https://msdn.microsft.com where I do a lot of my language searches.
Also, Microsoft has built a community where customers can ask questions and get data.
Tiobe has a nice document that clearly states which search enginers did not qualify and what the reason they didn’t qualify was.
- Microsoft.com: NO_COUNTERS
See: https://www.tiobe.com/tiobe-index/programming-languages-definition/
I would argue that a significant amount of searches for .Net languages are done primarily on Microsoft.com. I can only provide personal data. I often go directly to the source documentation on Microsoft.com and search on Microsoft’s site. And once I am there almost all further searches for .Net data occur there.
Microsoft has more C# developers in their company that many programming languages have world wide. Are they doing web searches through the list of qualified search engines?
Problem 5 – Better documentation
I hypothesize that the better the documentation, the less searching on the web is required. I also hypothesize that Microsoft is one of the best at providing documentation for it’s languages.
Because the documentation for .Net framework is so excellent, the question is usually answered in a single search instead of multiple searches that languages that are less well documented may require.
Problem 6 – Education
Colleges are teaching certain languages. Python and C++ are top languages taught in college. I would estimate that because of these, the languages primarily taught in college have far higher good search rates. Unfortunately, .Net languages, because of their former proprietary nature (which is no longer the case with the open source of .Net Core), were shunned by colleges.
It would be interesting to filter out searches by college students. Unfortunately, how would Tiobe know that a search came from a college student or not.
Problem 7 – Limited Verbage
Tiobe is only looking at certain words. The words that are being queried are:
- C#: C#, C-Sharp, C Sharp, CSharp, CSharp.NET, C#.NET
Further, Tiobe says:
The ratings are calculated by counting hits of the most popular search engines. The search query that is used is
+"<language> programming"
This problem piggy backs on Problems 3, 4, and 5. Visual Studio is so awesome, that we know exactly what we are looking for. As a C# developer, I don’t type C# into my searches hardly at all. I type something like: WebApi, WCF, WPF, System.Net.Http or Entity Framework or LINQ, Xamarin, and many other seaches. Microsoft documentation is so clear and specific (Problem 5) that we can do highly specific searches without including the word C#.
Yes, other languages have libraries, too, but do other languages have Microsoft’s marketing department that brands libraries with trademarks and logos and makes that brand the goto phrase to search? I don’t think there is a single other programming language other than C# that does this. Microsoft is lowing the web searches for C# by their awesome marketing.
This is further evidence to explain why the actual usage of C# has gone way up while the Tiobe index has gone way down. Asp.Net, Ado.Net, Razor, WCF, WebApi, WPF, WF, etc. What other language has logos and brands around specific parts of a language?
Problem 8 – Is C# always seen as C# in search engines
I don’t always add C# to my google searches. However, when I do, it is somehow changed to just C. The sharp symbol, #, is often removed. This recently stopped happening on Google, but it used to happen with every search in every browser. It was frustrating.
Has this been addressed in search engine stats?
Conclusion
The belief that C# is in the 3% range is an unfortunate error of circumstances. And .Net should be looked at is the second most important tool for a programmer, second only to Java, and above all other programming languages.